
Blog Post
Data Cleansing with the Medallion Method
Many businesses and organisations are struggling to produce trustworthy, accurate and consistent reporting due to poor quality source data, often described as dirty data. Here we focus on how we go about turning dirty data into curated quality data.

Data Cleansing with the Medallion Method
Many businesses and organisations are struggling to produce trustworthy, accurate and consistent reporting due to poor quality source data, often described as dirty data.
Our article "What is Dirty Data?" will provide further background on what it is along with the challenges and business impact of keeping your business information in such a chaotic way.
To ensure we’re making the right business decisions we need our data to be trustworthy and accurate. In last month's newsletter we focused on the importance of building a Single Source of Truth (SSOT) repository that could act as the central hub for all business reporting. This month we focus on how we go about cleansing, preparing and transforming the information we hold, from dirty to curated quality data.
While data cleansing may seem self-explanatory - we clean our data up so we can produce good quality reports and data driven decisions - Medallion Architecture may be more of a challenge. Medallion Architecture or the Medallion Method refers to a layered approach to preparing your data and describes the sequence of events taken to transform it from its raw state into your Single Source of Truth.
The Medallion Architecture
The Medallion method involves three stages; ingestion, cleansing and transformation, revolving around the Medallion Architecture in which your data is organised into three distinct layers:
- Bronze
- Silver
- Gold
Bronze Layer
The Bronze layer hosts raw, often dirty, data. No cleansing or transformation has been carried out. Data is stored "as is" in its original untampered with form, along with a complete history of all data imports or extractions. Data from this layer is not suitable for general reporting and data analysis, but could be used to support auditing of data, or reloading of silver and gold repositories. The Bronze layer acts as a Single Source of Truth for the data in its original state.
Consumers of Bronze data would include Data Engineers who are involved in the data preparation and storage processes for generating the Bronze, Silver and Gold data resources.
Auditors would also require access to Bronze data to ensure authenticity and compliance.
Silver Layer
The Silver layer hosts clean data. Our dirty/raw data has been passed through some processing to clean up, validate, integrate and transform it preparing it for analysis and reporting. Data exposed by this layer would be suitable for Data Scientists working on predictive analysis models but would not be suitable for general business reporting/analysis users. Our supporting article "What is Dirty Data?" provides further detail on the tasks typically carried out to prepare data for the Silver layer:
- Data de-duplication
- Data quality transformations and error corrections
- Normalisation and joining of entities
- Handling of nested semi-structured data
- Schema enforcement with data typing
The Silver data would be accessible to Data Engineers involved in the cleansing and preparation of Bronze data and could be made accessible to data scientists who are building complex models and require access to the detailed information located in the Silver layer.
Data De-Duplication
Data duplication can be caused by duplicate records within a single source system such as multiple records in a CRM system such as Dynamics or Salesforce with the same name and identical field values, or perhaps multiple records with the same name but different field values. Data duplication can also be caused by records created in independent, disparate systems such as customer records in a CRM system such as Dynamics or Salesforce, but also in a separate order processing system, and separate accounting system.
Decisions will need to be made to determine if records are really duplicates and should be de-duped, or whether they are in fact all part of the same entity and should be merged into a single record.
Data quality transformations and error corrections
Data quality issues can be anything from missing values, late arriving values, wrong values, NULL values, inconsistent data typing within a single field, mixed upper and lower case values.
All of these issues need to be addressed if a quality and complete data set is going to be presented to the business for reporting and analytics.
Some issues may simply have to be identified and reconciliation reports produced to enable corrections to the data at source. Other issues might be easily handled within the silver layer of your solution through coding in SQL, Python, ELT (extract, load, transform) pipelines.
Normalisation and joining of entities
No aggregation or rolling up of data should be carried out in the Silver layer. A record in the silver layer should represent a single instance of an object such as a single customer or a single line on an order. A record at the Silver level should not typically be something such as total order amount for a month. Aggregations generally belong in the Gold layer, but of course there are always exceptions to every rule and there may be a good business case for storing aggregate representations of data in the Silver layer - perhaps for performance reasons in some budget or technology restricted solutions.
Entities might be joined together in the Silver layer though, such as joining an order header record to an order line record to form a single table so it is easier to work with at the Gold layer and beyond.
Entities may also need to be joined where conforming several records into a single record, such as a conformed customer record built by joining CRM, order and financial information into a single customer record.
Handling of nested semi-structured data
Many modern applications expose their data via APIs that output JSON or XML extracts. At the high level the extract/output is a string, but within that string of data are elements, fields and metadata that enable a structured view of the data to be derived.
A decision will need to be made on how this semi-structured data is to be used and what should be stored or represented in the Bronze and Silver layers.
It is common to find both the semi-structured data stored in a VARIANT (generic data type) field along with structured data fields stored in individual fields derived from the semi-structured data. In some cases, such as when there are nested JSON elements within the JSON data, the semi-structured data may need to be normalised into separate entities within the silver layer.
Schema enforcement with data typing
The Silver layer needs to present structured data that can be passed to the Gold layer in a useable format for reporting and data analytics.
In the Bronze layer it is most likely that all source data is ingested into VARIANT or long text data type fields that are insensitive to source structural/data type changes. It is also likely that in the Bronze layer objects are created every time a load is run to ensure that structural changes are picked up and do not cause loads to fail due to differing formats. Applications go through continual development and new releases and so our medallion architecture solution needs to be resilient to these changes, ensuring no data loss as a result of change.
In the Silver level the generic data types will be cast as data types suitable to the field content - text, date, numeric. Entities within the silver layer will enforce a fixed schema to ensure that data can be manipulated/used in the desired way in the Gold layer.
Gold Layer
The Gold layer hosts our Single Source of Truth quality data that is exposed to and consumed by business users, data analysts, data scientists and machine learning engineers.
In the Gold Layer we will ensure that all entities are presented in a form that aligns with business logic and reporting/analysis requirements. Our Gold layer will be organised to ensure that performance is optimal when models, reports and dashboards refresh and execute queries against the Gold objects.
Within the Gold layer your data can be organised in such a way that you can produce high level summary reports without exposing or revealing sensitive information but the data none the less exists at a very detailed granular level and can be called on to produce very thorough and detailed analysis as required.
Building a Medallion Architecture Solution
The term Medallion Architecture is probably best known in the Lakehouse world, but this layered approach can be followed in more traditional data warehouse solutions, or hybrid Lakehouse and Data Warehouse solutions.
As we work on gathering all of our valuable data assets from the far corners of our business it is important that we can always trace the gold seal data consumed by reports and dashboards, back to its original source. With hundreds of fields and measures (KPIs) being drawn upon you need to know where to start if you suspect an issue with quality. To do this we need to be very methodical and organised, setting up inspection points that allow us to validate authenticity. For this reason, a single programmed solution that cleanses, transforms, joins and manipulates data in memory, and then outputs the final result to a stored location, is not enough.
Another requirement may be the ability to identify dependencies – where one change causes knock on effects for other specific data sets or core data elements. Let's suppose you are planning on implementing a new CRM system. You would need to know which reports, dashboards and AI/ML models are affected by this change.
One of the most important considerations when building a data solution is your security policy. Who should have access to the raw, clean and curated data? Are you able to easily restrict access or audit access to more sensitive data sets? Issues may arise if people gain access to unsuitable (dirty) data and try to use it for reporting and analysis. Then of course there are cases where we don’t want business users or data team members (data analysts/data engineers/data scientists) to get unauthorised access to data which is confidential or that they are not cleared to view.
Without an organised approach to moving your data through the various preparation stages from dirty/raw to clean and "Gold Seal" you will have great difficulty in making provision for:
- Data Authenticity, Lineage and Auditing
- Data Dependencies
- Point in Time/Version Control view of data
- Robust security model
Data Authenticity, Lineage and Auditing
Traceability, and the ability to inspect data at every part of its journey is key to gaining trust from business users, but is also extremely important where regulation and compliance rules require you to demonstrate data authenticity and to provide data lineage analysis.
You need to be able to answer the question; “Where did the data originally come from and what did it look like in its original form?”
The Medallion architecture lends itself to being able to inspect data at every stage of its journey from raw to ready to use.
Data Dependencies
Passing some form of data origin data through to final Gold entities will make it easier to determine which models, reports or dashboards will be impacted by a change to a data source, business application or service.
Silver and Gold entities can be designed to include metadata that identifies the original source or sources.
Point in Time/Version Control view of data
If a business user questions the validity or quality of data exposed in a report or dashboard you may need to be able to view the data as it was at a particular point in time that they are referring to as well as the current view of the data.
The Bronze layer should hold a complete history of imported data so that it is always possible to go back and see what data looked like at a specific point in time rather than just today.
Robust Security Model
All three layers of the Medallion Architecture solution should provide an appropriate security policy to ensure that access is given only to entities that are relevant to an individual and that they are authorised to view.
Location of Bronze, Silver and Gold Data
Whilst more commonly associated with cloud-based Lakehouse repositories the Medallion layered approach is a good one to take regardless of whether your data will be physically located in a Lakehouse or Data Warehouse.
In both Lakehouses and Data Warehouses typically schemas can be created which provide a perfect way of separating data at each stage of its journey from raw and dirty to quality and clean (From Bronze to Silver to Gold), but within a single catalogue for ease of management.
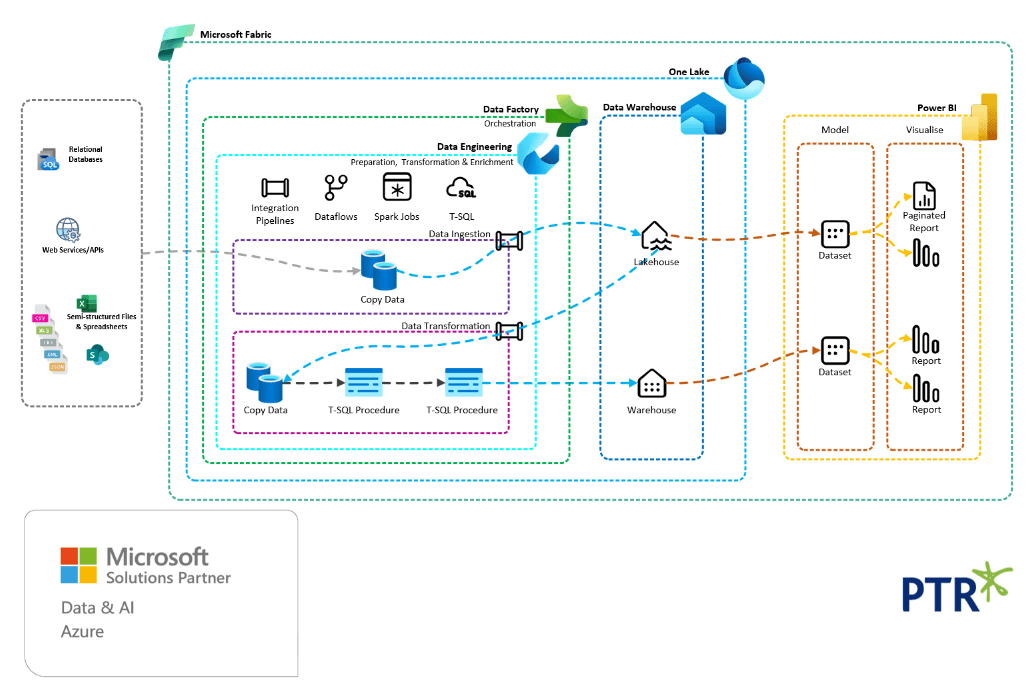
Here is an example of a single Microsoft Fabric Lakehouse with 3 separate schemas (a feature in preview at the time of writing in Match 2025):
It may be preferable to separate each layer out into completely separate catalogues to provide a simpler method of implementing a robust security separation at each layer.
Here is an example of a Microsoft Fabric set of Lakehouses, one for each layer:
Medallion Architecture WorkFlows
ELT toolsets often provide workflow templates that provide an easy means for you to follow the Medallion Architecture for your data solutions.
Microsoft Fabric Task Flows
For example Microsoft Fabric workspaces enable task flows to be created from a Medallion Architecture template:
- The green represents the extraction of the raw data
- The blue represents a storage layer of Bronze, Silver or Gold
- The purple represents the processes for cleansing, preparing and transforming the data at the Silver and Gold stages.
- The gold and red represent consuming the Gold data for reporting and analytics.
Selecting the New Work Item will give a selection of new object types relevant to the type of operation - get data, store data, process data.
Get Data
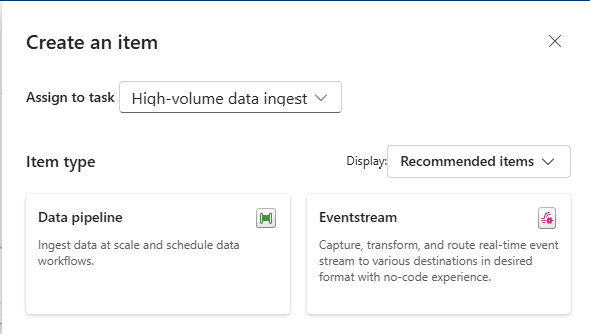
Get Data (High Volume):
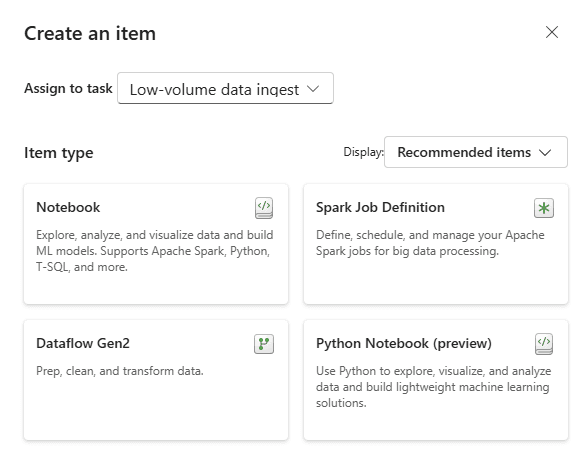
Get Data (Low Volume):
Store Data (Bronze, Silver, Gold)
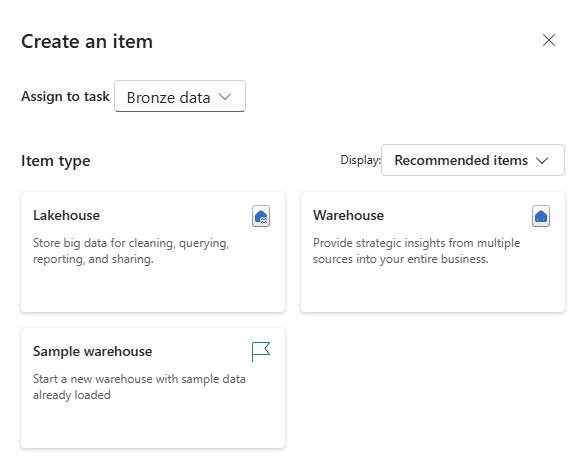
Prepare Data (Initial Process, Further Transformation)
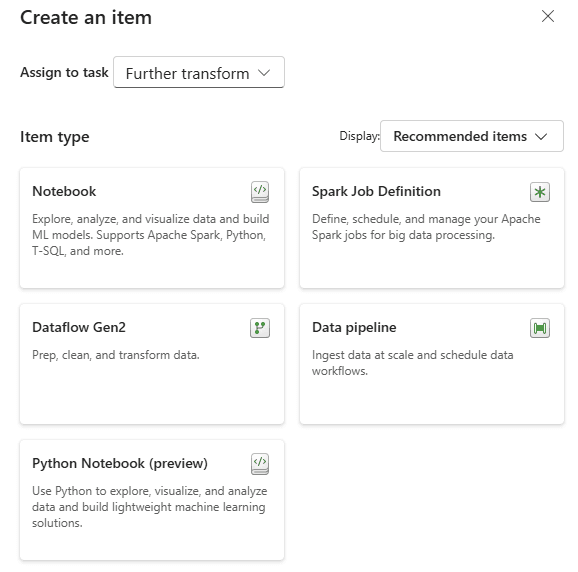
Visualise Data
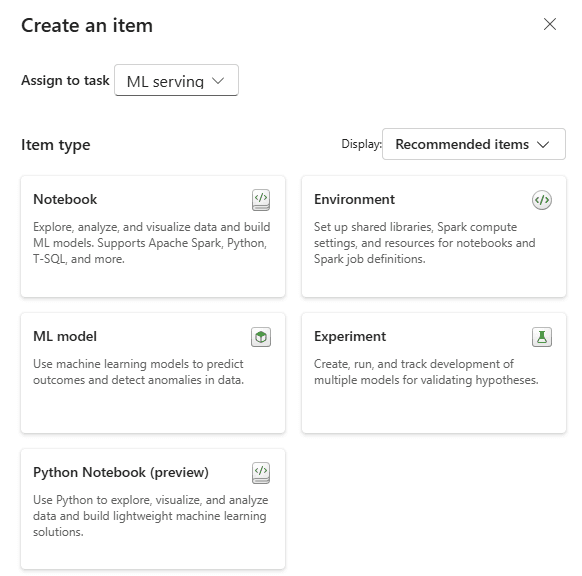
Analyse and Training Data - ML Serving
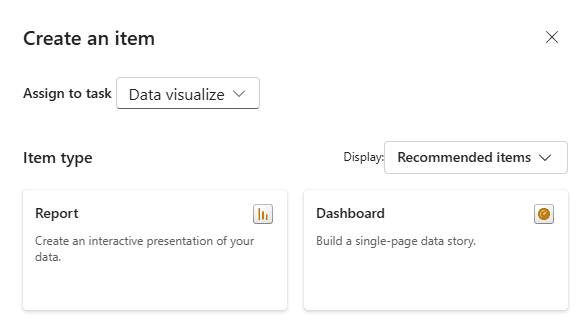
Analyse and Training Data - ML Serving
Conclusion
As with all things data there is no one right or wrong way to go about implementing your Data Analytics solution! The choices you make about storage and processing methods will be influenced by many factors including:
- Internal skill set and resource
- Budget
- Timeline
- Data source support
- Data Governance and compliance requirements
- Quality of source data
You would be very well advised to approach a data analytics solution with careful planning based on a solid data discovery and data strategy exercise before launching into an actual implementation.
Whether you follow a rigid Medallion Architecture approach to your data journey or choose another way, you must be methodical, organised and above all, ensure that you meet all your data governance and security requirements. Only then will you meet your goal of delivering high quality, trusted single source of truth data that will drive better business decisions and generate a good return on investment.
Our Data Analytics consultancy service gives you access to a complete team of experts from solution architects through to data engineers, data scientists and data analysts, all of which are complemented by our tailored training services to give your team the mentoring and support they need throughout your whole data journey.
Our Data Analytics consultancy and Data Strategy consultancy services give you access to a team of experts from solution architects through to data engineers, data scientists and data analysts, all of which can be complimented by our tailored and blended training services to give your team the mentoring and support they need throughout your whole data journey.
Please feel free to enquire here.
MD
Mandy Doward
Managing Director
PTR’s owner and Managing Director is a Microsoft certified Business Intelligence (BI) Consultant, with over 35 years of experience working with data analytics and BI.
Related Articles
Frequently Asked Questions
Couldn’t find the answer you were looking for? Feel free to reach out to us! Our team of experts is here to help.
Contact Us