Tech Tips
The Illusion of Expertise: Why Prompt-Engineered Data Strategy Fails
AI is making it extremely easy to "Do It Yourself" in the data world. This may be creating an illusion of "Expertise".

AI is making it extremely easy to "Do It Yourself" in the data world. This may be creating an illusion of "Expertise".
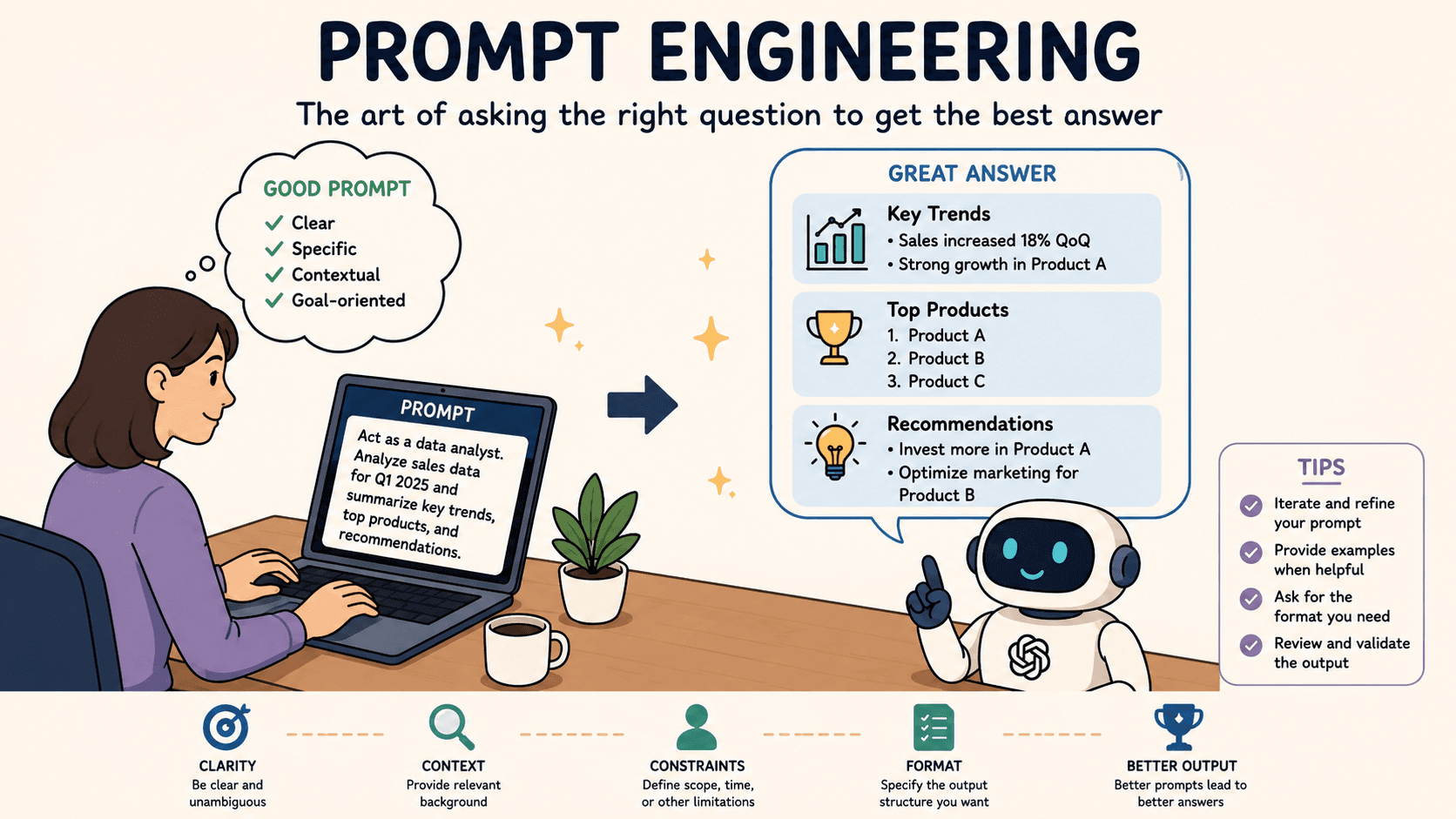
If you know how to phrase a question and provide context and structure you will be more likely to succeed in solving a problem or getting an accurate and trustworthy answer from AI.
Ask a question with no context and structure and you have just wasted your time and saved none.
Context and structure eliminates the guesswork and allows AI to do what it is good at and give you trustworthy, accurate and usable responses that save you time.
The art of success with AI comes from quality Prompt Engineering and quality fit for purpose data.
Prompt Engineering is a term that has come into the day to day life of anyone who has embraced the AI world and dipped their toe in the water. For those of you not familiar with the term there is a brief explanation of what it is a little later.
In a nutshell for prompt engineering to be successful the human asking the questions needs to have a good understanding of the business and technical landscape in order to generate quality, accurate and trustworthy results.
A little knowledge is a dangerous knowledge
There is a saying "A little knowledge is a dangerous knowledge"! Let's explore this.
If you do not have an all-round knowledge and understanding of a business requirement and expert technical skills and, maybe more importantly, real world experience, how can you be sure that you are framing your requests to AI models with all the important parameters that will drive the right answers, responses or actions for you?
Yes, you will get an answer from the various AI tools such as Gemini, Chat GPT, Copilot, Claude, but:
If you do not fully understand the business requirement how will you know if the logic that AI has imposed is correct?
If you do not have an overarching understanding of technical platforms, coding languages, data governance and compliance requirements, implications on resource availability and usage, and more then how will you know if any AI generated code is accurate, safe, scalable and performant?
What many organisations are now seeing is a pattern forming where initial development times are dramatically reduced as development teams embrace AI and use AI tools to generate not just code, but complete reporting, analytics, automation and decision making solutions.
The reality is that once moved into testing serious flaws are often discovered that impact accuracy and performance, caused by issues such as:
loose or inaccurate logic assumptions leading to incorrect outputs and actions
poor security assumptions that lead to data breaches
lack of consideration for performance and resource consumption that push operational costs up
AI generated solutions crashing live systems during peak times
Along with this comes an increased risk to your entire data and application infrastructure and increased development cost rather than a reduction in development costs due to parsing AI generated code and solutions and the reworking of poorly generated code and solutions.
Worst case scenario is such projects are abandoned as the overhead of wading through and untangling messy AI generated code in different styles and sometimes different languages can have a higher cost than starting again, or deciding to stick with what you already had.
The Accidental Data Engineer
Business users are now trying to do what data engineers have previously been tasked with and they are succeeding to a point. They are producing applications, BI and AI solutions with no technical training as the AI tools are enabling them to do so.
The trouble is they are lacking in the foundational training and experience in areas such as data governance, security protocols, and documentation standards, not to mention the years of data platform and technical skills such as Database design, SQL coding, query performance.
Yes you can ask AI to build a dashboard from the bottom up - give it the data and ask it to calculate a business metric and generate a dashboard.
BUT…..
Can you spot the logic error
that double counted values due to an incorrect database structure interpretation
or sent out 50% discount incentive options to users to encourage resubscription when all that had happened was their payment card expired?
Did you catch it before it cost the business money?
Could you foresee that the minute you started loading live data the hosting environment costs would spiral up due to resource usage?
Did you catch it before you racked up platform subscription costs?
Did you catch it before it crashed your entire business applications during a peak time?
Could you spot that your new app had inadvertently exposed data in dashboards that should be confidential?
Did you catch it before you had to invoke a major security breach protocol?
Writing code is only 10% of data engineering. The other 90% is data governance, security, scalability, and error handling.
The prompt-engineer only sees the 10%, such as the functioning dashboard. They are completely oblivious to the fact that their AI generated solution might be exposing sensitive customer data or slowing down the company's core database.
A real danger of forging ahead with accidental data engineers running with AI driven solutions is that the real data engineers then waste valuable time firefighting preventable fires, which can grind the more strategic business analytics to a halt.
The Illusion of Expertise is Twice as Dangerous
Don't underestimate the power or experience and knowledge.
If your AI empowered "development team" does not know what they don't know you have a huge risk and vulnerability. People making mistakes may move to people thinking they are experts and making mistakes.
This is twice as dangerous:
Those who are technically expert have real world experience to guide them through potential pitfalls and future challenges, They will seek advice, validation and confirmation and are likely to test robustly.
Non technical users who think they experts will assume they have all the knowledge they need (they don't know any different) and will confidently make mistakes without even realising.
Fabricated, corrupted or flawed data could be passed as absolute truth to key decision makers.
Share This Post
Mandy Doward
Managing Director
PTR’s owner and Managing Director is a Microsoft certified Business Intelligence (BI) Consultant, with over 35 years of experience working with data analytics and BI.

Frequently Asked Questions
Couldn’t find the answer you were looking for? Feel free to reach out to us! Our team of experts is here to help.
Contact Us