
Technology
Planning and Executing Data Cleansing
We have all experienced the pain of poor-quality data, challenging and time consuming to turn into meaningful, accurate and trustworthy data. How do we transform dirty data into to clean, error-free, useful data for reporting and analytics needs?

Planning and Executing Data Cleansing
We have probably all experienced the pain of poor-quality data and how challenging and time consuming it can be to produce meaningful, accurate and trustworthy reports from it.
Over the last few months we have discussed:
- - suited to hosting our entire data journey from source to dashboard
- and how it can play an important role in our BI projects with the right AI and Data Strategy
- - to ensure the whole business community is reporting from a central trusted, accurate data set for all reporting and analytics)
- - to ensure we have a complete history of the untampered true raw data, a clean, validated, integrated and error free dataset ready for analytics and AI, and our modelled, trusted data aligned with business logic, ready for optimal dashboard consumption.
In this month's newsletter we focus on the Data Cleansing process itself.
How do we go about the actual transformation process that takes our data on its journey from dirty to clean, error-free, useful data for our reporting and analytics needs?
I have summarised the process of data cleansing into 8 simple steps:
- Step 1: Planning
- Step 2: Data Discovery
- Step 3: Data Profiling
- Step 4: Correct at Source or Correct in ELT?
- Step 5: Clean
- Step 6: Validate
- Step 7: Publish
- Step 8: Documentation
The first three steps are about surveying your data estate, finding out where your data is located and then profiling the data sources to see what data quality challenges you are going to face along the way.
The last 3 steps are likely to be iterative, repeated over time as source data has a habit of changing. Applications are updated or customised, new fields and extra drop-down choices added, new modules implemented. We cannot simply publish and forget.
Once cleansed data is published it is vital that you have some form of reporting that will identify if any load or transformation failures have occurred. You will then need to go back to Steps 3 to 5 to address the issue and then off we go again with steps 6, 7 and 8.
Further food for thought is how AI might assist with our data cleansing journey. That question is addressed in this How can I use the power of AI for Data Profiling and Cleansing? article.
Step 1: Planning
It may be tempting to delve straight into attacking our dirty data without a plan but this can be terribly inefficient in the long run. As data quality scenarios are uncovered and unexpected challenges present themselves, we may discover that the data cleansing toolset we chose initially was not right for the task, leading to extremely complex or even aborted attempts. We might also find out too late that data governance and compliance requires us to demonstrate transparency on the origins of our data and what has happened to it along the way. Not all tools lend themselves to doing this on the hoof, resulting in a very time consuming, often manual, and costly exercise as we try to rectify this further down the line.
There are always going to be challenges with data quality that require some thought and even several attempts to find a solution. But planning your Data Cleansing journey from the start will save a lot of pain, frustration and time as well as money if you start missing target dates etc.
Choosing the right toolset for the job will result in a more efficient project and will make life easier for all involved in the data cleansing process.
What are important factors in your toolset choice?
- Number of data sources
- Format of data sources
- Volume of data and size of source data sets
- Medallion architecture being followed
- Security requirements
- Performance - real time or batch runs
- Complexity of transformations
- Audit trail of transformations carried out from source to destination
- Exception Reporting
- Documentation
- Resource and team skill set
- Project timeline
- Project budget
Whatever toolset you choose to prepare data for analytics there will always be some data cleansing challenges that require an element of lateral thinking and some clever coding. Your tool selection will simplify this task.
What tools could we use?
There are many, but probably the most common tools being used are the following:
- Excel
- SQL
- Python
- PowerQuery Dataflows
- Data Factory pipelines
- Databricks
By starting with a data discovery and data profiling exercise you can put yourself in a much better place to select the right tools for the job - and yes, you could select multiple tools within a single project.
On a more conceptual level we will also be in a position to decide if we are going to follow a Medallion Architecture process for our data cleansing exercise.
Step 2: Data Discovery
Data Discovery is about working with the business users - the data owners - to locate the source data you need for your reporting and data analytics solution and working out how you are going to retrieve it. During this stage you will, for example, be able to identify if data is going to be delivered to you in a nice structured, data typed and consistent format or in an inconvenient CSV format, or perhaps a more complex semi-structured format such as JSON or XML.
The type of data source will influence the toolset you choose for your data cleansing project.
Step 3 - Data Profiling
Data Profiling is about getting to grips with what your source data looks like. We have identified a few of the challenges we might find in previous articles, but here’s a summary of the main issues discovered during data profiling:
- Within a Single data source
- Missing values
- NULL Values
- Duplicate Values
- Mixed data types or formats
- Dates as strings
- Dates as UTC numbers
- Telephone numbers as numbers
- Single values containing multiple values such as lists
- Single values multiple fields such as single fields with whole address, single field with title, first name, middle name and surname.
- Data values at the wrong grain such as order totals and delivery totals stored with a line on an order
- Across data sources
- Variations of common entities such as customers and products
- Variations in data types used for common information such as dates
- Orphan records such as an order that has no corresponding customer record
- Childless records such as an emergency call made, but no visit associated with it
What tools can we use?
PowerQuery
Power Query offers some fantastic data profiling tools that give you a nice overview of data quality within every column of a table:
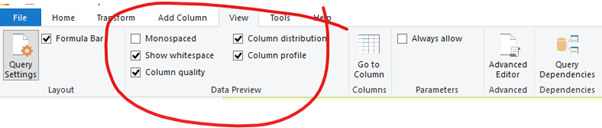
The following example shows a breakdown of valid, error and empty values for a subset of source fields along with an indication of the data distribution – distinct and unique values:

PowerQuery is available within Excel, Power BI , Fabric and Azure Data Factory.
SQL
The SQL language is a perfect data profiling tool for structured data. The flexibility of the language makes coding for common data scenarios such as those listed above relatively straight forward. It offers a wide library of functions perfect for this challenge such as aggregate functions (COUNT, SUM, MIN, MAX, AVG, STDEV, VAR), powerful string functions ( LEN, SUBSTRING, CHARINDEX, UPPER, LOWER, TRIM), and data value check functions (ISDATE, ISNULL, ISNUMERIC)
Python
Python is a powerful scripting language offering some very useful libraries of data profiling utilities. For example pandas-profiling and ydata-profiling.
Microsoft Fabric
Microsoft fabric is an integrated data and AI platform so you have access to all the tools you need in one place.
Microsoft fabric supports PowerQuery dataflows, SQL queries against lakehouse and warehouse tables making the SQL function library available to us, and Notebooks that give us access to Python data profiling libraries such as ydata-profiling.
Step 4: Correct at Source or Correct in ELT?
Some data issues should really be handled in the generating source systems, which might require some changes to your usual, regular business processes. We should be asking, “Are our data entry procedures consistent and appropriate for our reporting and analytics needs? Could a few changes to our data entry procedures right at the start help us to achieve better quality data in the future?” This might not fix issues with historic data but can help ensure more accurate data quality from the source system going forward. For example, you could force certain fields to be populated, put some data entry constraints on fields to limit the choices and avoid free text entry.
Any data which cannot be cleansed/fixed at source will need to be passed through our data cleansing process.
They do say “Garbage in, garbage out”! So if you can clean the garbage at source you have nice clean data all the way through.
Step 5: Clean
With the source data located, data formats identified, data profiling carried out and the most appropriate toolset chosen we are now good to go with the actual cleansing process.
We talked about this process in our Medallion Architecture article. If we are opting to implement the Bronze, Silver and Gold layers associated with Medallion Architecture we will need to be mindful that not only do we need to cleanse and transform our data, we also need to consider if we need to capture every transformation that has been applied to our data and where the cleansed data and the transformation history will be stored. Make sure you have enough data inspection points along the way in your data journey.
Always plan for future changes in your source data when you are implementing data cleansing techniques. Try to be as generic as you can when coding, avoiding hard coding of values wherever possible and dynamically coding such values instead or implementing parameter and config files to drive the transformations. Ask yourself at each step of cleansing "How easy will it be to handle a different scenario? Is there anything I can do now that will make changes easier later?”
Putting complex transformations that require multiple steps into a single code line might look impressive, and might make your resulting script shorter, but nesting too much logic can make it difficult to unravel and adapt at a later date. Modular can be better from a maintenance and support perspective.
Performance is also an important consideration and sometimes simplification of code, breaking transformation logic into more modular blocks, can lead to poorer performance. If your data cleansing pipelines are only running over night or a few times a day an extra 10 minutes may not be an issue. If you are implementing more real time reporting and analytics solutions then performance will be more important, but you might not need to trade your simplification for performance, you may just need to select a different tool. For example, using Databricks with SQL or Python to execute transformation code may be more efficient than running SQL stored procedures within a database instance.
Data Cleansing with Excel
Challenges
Formulae can be easily overwritten or amended resulting in undesirable logic changes. Not suitable for large data sets, or multiple data sets.
Benefits
Accessible and easy to use. Everybody has it.
Method
Excel formulae, VLOOKUP and HLOOKUP used to join datasets.
Data Cleansing with SQL
Challenges
SQL is a coding solution. Knowledge of the SQL language and use of functions required. A more technical solution than Excel.
Benefits
Excellent handling of large data sets, ideal for integrating multiple datasets, many functions to assist with transformation steps. More efficient, scalable, secure and resilient than Excel solutions
SQL is a standard BI and data platform language that is a common skillset within a BI team.
Method
Code SQL functions, stored procedures and views, or use Notebooks to launch SQL code.
Data Cleansing with Python
Challenges
Less common skillset and a coding solution.
Benefits
Extensive libraries that offer powerful functions for data cleansing and transformation. Suitable for large datasets. The use of Notebooks and Python can provide very good performance on very large datasets.
Method
Code in Python Notebooks.
Data Cleansing with Data Factory Pipelines
Challenges
Less common skillset. Can be more costly than a coded solution such as SQL or Python.
Benefits
Visual interface. Task flow and dependencies.
Method
Create pipelines that consist of dependent or parallel tasks. Tasks can be native data factory tasks such as copy tasks, or calls to SQL stored procedures and Python Notebooks.
Data Cleansing with Power BI and Fabric PowerQuery Dataflows
Challenges
Requires access to Power BI or Fabric.
Benefits
Visual tool with powerful built-in data cleansing and transformation utilities.
Method
Create Queries that consist of Applied Steps.
Data Cleansing with Databricks
Challenges
More complex/technical solution.
Benefits
High performance on large datasets and extensive libraries of functions available in either Python or SQL.
Method
Create Notebooks which in turn can be called from a Data Factory pipeline.
Step 6: Validate
Once your data has been cleansed it is extremely important to validate the cleansed data, compare it against original source and look for any anomalies.
This is not a one-off activity. Data changes over time. New records are input to source systems which can raise new data quality challenges. Fields that were all populated, are now not always populated. Fields that were a date data type are now text data type. Fields that had a limited list of values, now have some new values coming through.
Step 7: Publish
When you are happy that your data cleansing is in a good place you will want to publish the clean data so that it can be consumed by those that need it - your data engineers, data analysts and data scientists.
If you are following the Medallion Architecture approach you will have brought your raw data into a Bronze layer repository, and the cleansed data will be published to your Silver layer repository.
As a part of the Publish stage it will be important to draw up procedures for monitoring the data cleansing process.
- How can you identify if a transformation or load has completed?
- Who will be monitoring the load or will you have alerts generated by text or email?
- What is the expected turn around for fixing any issues identified?
Step 8: Documentation
All good Data Cleansing journeys should have supporting documentation that outlines the overall workflow, data sources, tool sets implemented, data challenges, supporting business procedures or rules, and an architecture diagram of the overall solution.
In addition to technical documentation, you may also ned to think about providing exception reports to support data profiling / data discovery issues, and data lineage audit trail documentation to support any data governance or compliance requirements you have.
Don’t leave it until the end to think about your documentation, particularly data transformation audit trails as it is very difficult to reverse engineer code already written to extract this at a later date.
Summary
You have a wide selection of data platforms and tool sets at your disposal for all your data cleansing needs, but careful planning is the key to selecting the right one!
It can be daunting launching into such a project as there is so much choice. PTR specialise in helping clients find the most appropriate solution for their data needs and as Microsoft Solutions Partner AI & Data Azure, we are very well placed to support and mentor you and your team as you embark on your data journey.
MD
Mandy Doward
Managing Director
PTR’s owner and Managing Director is a Microsoft certified Business Intelligence (BI) Consultant, with over 35 years of experience working with data analytics and BI.

Frequently Asked Questions
Couldn’t find the answer you were looking for? Feel free to reach out to us! Our team of experts is here to help.
Contact Us